Those lemmata are considered key ones the frequencies of which statistically surpass – in the poem – their frequencies in the total of the Corpus of Czech Poetry. Statistical significance is, at the same time, verified via χ2 test with Yates' correction , and log-likelihood test. An user is free to specify whether the tests will operate at the α = 0,001 significance level (i.e., with the 0.1% risk that a lemma the high frequency of which is only a matter of randomness will be declared a keyword), or at the α = 0,01 one (with the 1% risk of the same). Besides this, a user can specify which parts of speech should be excluded from the keyword analysis (in the default mode, only nouns, adjectives, and verbs are permitted), declare the minimal number of lemma occurrences in the poem needed for it to be considered it a keyword, and select a corpus of reference (i.e., whether the values will be compared with the whole corpus, or with the works of the given author only).
For a keyword analysis in user's own texts, we recommend the application KWords, which was designed by the Institute of the Czech National Corpus (Faculty of Arts, Charles University) and which served for us as inspiration for Hex.
Those lemmata are considered key ones the absolute frequencies of which are higher than their positions in the rank-frequency distributions of the given poems (they occur in the poems more often than the ranks of their frequencies are); cf. Čech-Popescu-Altmann 2014.
Help
Word
It is possible to insert any lemma into the field "word"; for this lemma, poems will be looked for in the database which contains it as a keyword. The search does not take into account letter case; it is based upon precise wording and strict distinction of diacritics – for example, poems containing keyword "třpyt" will be found in searches for "třpyt", "Třpyt", as well as "TŘPYT", but not in searches for "trpyt" or "trpy".Author
Searching can be restricted to works of individual author(s). The choice is performed with the assistance of autocomplete.From/To
The From/To field serves to delimit the period of the search – e.g., from 1850, to 1870. In searches covering one year only, it is necessary to fill in both the fields – e.g., for 1820: from 1820, to 1820.Part of Speech
It is used to restrict searching to one part of speech only. It is possible to use it to dispose of homonyms, such as "stát" (a state; a noun) / "stát" (to stand; a verb).Method
Searching for keywords, or thematic words?Minimal Frequency
Minimal required frequency of the lemma for it to be included among key/thematic ones.Significance Level
Statistical test significance level (keywords only).Corpus of Reference
Comparing the frequency of a lemma with its frequency in the entire corpus, or in the other works of the same author only? (Keywords only.)Result
The result of the search is presented in a chart and a table::
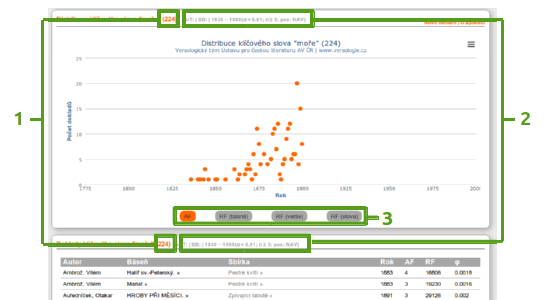
Heading
The headings of the chart and the table present the number of findings (1), i.e., the total of poems in which the keyword (given the predefined filters) was found, as well as the sum of the used filters (2) in the form of a|b|c(d;e;f):(a) AUT: the sequence specifying the author
(b) SB: the sequence specifying the collection (unavailable in Mode 1)
(c) the period (if given)
(d) the selected significance level
(e) the selected minimal frequency
(f) the required parts of speech (A – adjective, C – numeral, D – adverb, I – interjection, J – conjunction, N – noun, P – pronoun, R – preposition, T – particle, V – verb)
Chart
The chart contains the frequency of poems (findings) containing the given keyword in particular years. The displays may be switched over, if needed (3):(b) RF (of a poem): relative frequency in relation to a number of poems, i.e. the number of findings in particular years divided by the total of poems published in the given year
(c) RF (verše): relative frequency in relation to a number of lines, i.e. the number of findings in particular years divided by the total of lines in the poems published in the given year
(d) RF (slova): relative frequency in relation to a number of words, i.e. the number of findings in particular years divided by the total of words in the poems published in the given year
By clicking the mouse button, it is possible to see details of a section of the chart.
Table
The table contains all the findings:[Autor] author of the poem
[Báseň] name of the poem followed by a link to a list of all its keywords
[Sbírka] name of the collection the finding comes from, followed by a link to the full text of the collection in the Czech Internet Library
[Rok] year of the collection publication
[AF] absolute frequency, i.e. the number of occurrences of the keyword in the poem
[RF] relative frequency, i.e. the number of occurrences of the keyword in the poem divided by the total of words in the poem
[φ] φ coefficient = (χ2 / n)0,5
Poetry Collection/Poem
"Poetry Collection" and "Poem" filters futher specify the scope of the analysed texts. In the same way as the "Author" filter, they do not take into account letter case, being based upon strict use of diacritics and upon the match of the written sequence with the beginning of the name of the poem/collection. For example, if sequence "di" is written in the "Poetry Collection" field, the analysis will include titles "Divotvorný snář", "Divadelní popěvky", "Divoká labuť", and "Divoké ovoce", but not "Díkůvzdání", or "Podivné jitro". The "|“ sign is of the same function as the logical operator OR – i.e., if sequence "sní|taj" is written in the "Poetry Collection" field, the analysis will include collections "Sníh", "Tajemné dálky", and "Tajemná sfinx".Sorting
A user may choose among alphabetical sortings based upon author's names, poetry collection names, years of publication, poem names, or (s)he may opt to generate a frequency list of the selection.Result
The heading of the result card shows the sum of filters (see above).Every poem is presented as a separate entry containing:
(1) author's name, poem name, collection name, and year of publication
(2) list of keywords (the letter in brackets indicating the part of speech; see above)
(3) link to a page with the detail of the poem
Result – List of Frequencies
The list of frequencies contains an inventory of the total of keywords found (given the predefined parameters) in the specified scope of texts in the following form:(1) number of poems in which the keyword was found
(2) keyword
(3) part of speech (see above)
How to quote
Plecháč, Petr (2017). Hex 2.0. Keyword in Czech poetry. Prague: Institute of Czech Literature, CAS. Available at <http://versologie.cz>.
Why "Hex"?
"There are more than five hundred known spells to secure the love of another person, and they range from messing around with fern seed at midnight to doing something rather unpleasant with a rhino horn at an unspecified time, but probably not just after a meal. Was it possible (the enquiring minds enquired) that an analysis of all these spells might reveal some small powerful common denominator, some meta-spell, some simple little equation which would achieve the required end far more simply, and incidentally come as a great relief to all rhinos? To answer such questions Hex had been built."
(Terry Pratchett: Interesting Times)