Jako klíčová jsou určena ta lemmata, jejichž frekvence v dané básni statisticky významně převyšuje jejich frekvenci v celém Korpusu českého verše. Statistická významnost je ověřována zároveň
testem χ2 s Yatesovou korekcí a testem log-likelihood. Uživatel má možnost specifikovat, zda budou testy provedeny na hladině významnosti α = 0,001 (tedy s 0,1% rizikem, že za klíčové slovo bude chybně označeno lemma, jehož vyšší frekvence v dané básni je pouze dílem náhody) nebo α = 0,01 (tedy s 1% rizikem téhož). Spolu s tím má uživatel možnost specifikovat, které slovní druhy mají být z analýzy klíčových slov vypuštěny (ve výchozím stavu jsou povolena pouze podstatná jména, přídavná jména a slovesa), určit minimální počet výskytů lemmatu v básni potřebný pro zařazení mezi klíčová slova a zvolit referenční korpus (zda budou hodnoty porovnány s celým korpusem nebo jen s díly daného autora .
Pro analýzu klíčových slov ve vlastních textech doporučujeme aplikaci KWords vyvinutou Ústavem českého národního korpusu FF UK, jíž jsme se při tvorbě Hexu nechali inspirovat.
Jako tematická jsou označena ta lemmata, jejichž absolutní frekvence je vyšší, než jejich pořadí v rankové frekvenční distribuci dané básně (objevuí se v básni víckrát, než kolikáté nejfrekventovanější jsou), srov. Čech-Popescu-Altmann 2014.
Nápověda
Slovo
Do pole „slovo“ lze zadat libovolné lemma, pro nějž budou v databázi vyhledány básně, v nichž se objevuje coby klíčové slovo. Hledání nezohledňuje velikost písmen, je založeno na přesném znění a striktním rozlišení znaků s diakritikou, například básně obsahující klíčové slovo „třpyt“ budou nalezeny při zadání „třpyt“, „Třpyt“ i „TŘPYT“, ale nikoliv při zadání „trpyt“, či „třpy“.Autor
Vyhledávání lze omezit na dílo autora/autorů. Výběr probíhá s pomocí našeptávače.Od/do
Pole od/do slouží k omezení časového rozmezí, v němž bude vyhledávání probíhat. Např. od 1850, do 1870. Při vyhledávání v jednom konkrétním roce je nutné vyplnit obě pole, např. pro rok 1820: od 1820, do 1820.Slovní druh
Omezit vyhledávání na určitý slovní druh. Lze využít k filtrování homonym jako stát(substantivum) / stát(sloveso).Metoda
Vyhledávat klíčová nebo tematická slova?Minimální četnost
Minimální požadovaná četnost lemmatu, aby mohlo být počítáno mezi klíčová/tematická.Hladina významnosti
Hladina významnosti statistického textu (pouze klíčová slova).Referenční korpus
Porovnávat frekvenci lemmatu s jeho frekvencí v celém korpusu nebo jen v ostatních dílech daného autora? (pouze klíčová slova).Výsledek
Výsledek vyhledávání je zobrazen prostřednictvím grafu a tabulky:
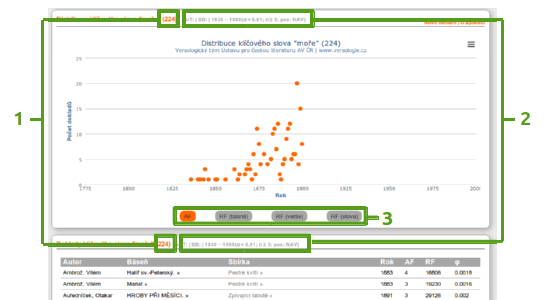
Záhlaví
V záhlaví grafu i tabulky je zobrazen počet dokladů (1) , tj. celkový počet básní, v nichž bylo (při zadaných filtrech) nalezeno hledané klíčové slovo, a souhrn použitých filtrů (2) ve formátu a|b|c(d;e;f):(a) AUT: řetězec specifikující autora
(b) SB: řetězec specifikující sbírku (v módu 1 nedostupný)
(c) časové rozmezí (pokud bylo zadáno)
(d) zvolená hladina významnosti
(e) zvolená minimální četnost
(f) povolené slovní druhy (A – přídavné jméno, C – číslovka, D – příslovce, I – citoslovce, J – spojka, N – podstatné jméno, P – zájmeno, R – předložka, T – částice, V – sloveso)
Graf
Graf zobrazuje četnost básní (dokladů) obsahujících zadané klíčové slovo v jednotlivých letech. Zobrazení je možné přepínat (3):(a) AF: absolutní frekvence, tj. počet dokladů v jednotlivých letech
(b) RF (básně): relativní frekvence vzhledem k počtu básní, tj. počet dokladů v jednotlivých letech dělený počtem všech básní publikovaných v daném roce
(c) RF (verše): relativní frekvence vzhledem k počtu veršů, tj. počet dokladů v jednotlivých letech dělený počtem všech veršů obsažených v básních publikovaných v daném roce
(d) RF (slova): relativní frekvence vzhledem k počtu slov, tj. počet dokladů v jednotlivých letech dělený počtem všech slov obsažených v básních publikovaných v daném roce
Označením myší lze zvětšit detail výseku grafu.
Tabulka
Do tabulky jsou promítnuty všechny doklady:[Autor] autor básně
[Báseň] název básně spolu s odkazem na soupis všech klíčových slova v básni
[Sbírka] název sbírky, z níž doklad pochází spolu s odkazem na plný text sbírky v České elektronické knihovně)
[Rok] rok vydání sbírky
[AF] absolutní frekvence, tj. počet výskytů klíčového slova v básni
[RF] relativní frekvence, tj. počet výskytů klíčového slova v básni dělený počtem všech slov v básni
[φ] koeficient φ = (χ2 / n)0,5
Sbírka/báseň
Filtry „sbírka“ a „báseň“ dále specifikují okruh analyzovaných textů. Stejně jako filtr „autor“ nezohledňují velikost písmen, jsou založeny na striktním rozlišení diakritiky a shodě zadaného řetězce s počátkem názvu básně/sbírky. Například při zadání řetězce „di“ do pole „sbírka“ budou do analýzy zahrnuty tituly „Divotvorný snář“, „Divadelní popěvky“, „Divoká labuť“ a „Divoké ovoce“, ale nikoliv „Díkůvzdání“, nebo „Podivné jitro“. Symbol „|“ slouží jako logický operátor OR, tzn. při zadání řetězce „sní|taj“ do pole „sbírka“ budou do analýzy zahrnuty sbírky „Sníh“, „Tajemné dálky“ a „Tajemná sfinx“.Řazení
Uživatel může zvolit, zda mají být výsledky abecedně řazeny dle příjmení autora, názvu sbírky, roku vydání, názvu básně, nebo zda má být generován frekvenční seznam výběru.Výsledek
V záhlaví karty s výsledkem je zobrazen souhrn filtrů (viz výše).Každá báseň je pak zobrazena jako samostatný záznam obsahující:
(1) jméno autora, název básně, název sbírky a rok vydání
(2) seznam klíčových slov (písmeno v závorce označuje slovní druh; viz výše)
(3) odkaz na stránku s detailem básně
Výsledek – frekvenční seznam
Frekvenční seznam zobrazuje soupis všech klíčových slov nalezených (dle zadaných parametrů) ve specifikovaném okruhu textů ve formátu:(1) počet básní, v nichž bylo dané klíčové slovo nalezeno
(2) dané klíčové slovo
(3) slovni druh (viz výše)
Jak citovat
Plecháč, Petr (2017). Hex 2.0. Klíčová slova v české poezii. Praha: Ústav pro českou literaturu AV ČR. Dostupné z <http://versologie.cz>.
Proč „Hex“?
„Existuje více než pět set známých návodů, s jejichž pomocí si člověk může zajistit lásku milované osoby, a ty zahrnují širokou škálu činností od použití pylu kapradin o půlnoci až po něco velmi nepříjemného, co se provádí nosorožčím rohem v libovolném čase, i když pravděpodobně ne po jídle. Bylo by možné (říkají si ti lidé obdaření pátravou myslí), že bychom mohli pečlivou analýzou oněch návodů odhalit nějakého sice malého, ale mocného společného jmenovatele, nějaké metazaklínadlo, malou jednoduchou rovnici, která umožní dosáhnout požadovaného výsledku rychleji a jednodušeji, a tak přinést nesmírnou úlevu všem nosorožcům? Hex byl postaven právě proto, aby dával odpovědi na podobné otázky.“
(Terry Pratchett: Zajímavé časy)